概述
在测试cephfs的性能中,发现其direct IO性能较差,而rbd的direct IO性能就较好,很奇怪为什么,这里做测试对比和分析
性能测试
rbd设备
1 | # rbd create test -p cephfs_data3 --size=1024 |
cephfs
1 | # mount -t ceph 10.10.2.1:6789:/foo mike -o name=foo,secret=AQCddEtZC8n5KRAAPw5qd3BWLzlgqiEuRR5AYg== |
结论:为什么对于direct IO,rbd与cephfs的差别这么大?
分析
cephfs
代码分析
cephfs client端写操作接口:
1 | const struct file_operations ceph_file_fops = { // cephfs中文件的file操作集 |
针对direct IO的处理过程如下:
1 | static ssize_t ceph_write_iter(struct kiocb *iocb, struct iov_iter *from) |
所以从上面的逻辑看:cephfs写direct IO是会被切分为一个个写osd的request,顺序的每个osd request都会等待写成功返回。这样就无法发挥出分布式集群的整体性能,所以cephfs的direct IO写性能较低。
测试验证
按照 cephfs kernel client debug 方法 打开cephfs client端的log,测试一个12M的direct IO;
命令:dd if=/dev/zero of=file bs=12M count=1 oflag=direct
log信息:
1 | [260262.367080] aio_write ffff8801f403b418 10000002393.fffffffffffffffe 0~12582912 getting caps. i_size 0 |
测试增大object size
增大cephfs中file对应的object size和stripe unit都为64M,然后测试性能
1 | # touch file |
测试性能发现,对比4M的object size和stripe unit,性能并没有提升。
分析osd端的op时间开销
获取cephfs文件的数据的location信息:
1 | # cephfs file show_location |
在osd 25上打开optracker:
1 | 修改/etc/ceph/ceph.conf,在osd域添加下面两行: |
重新跑dd命令后,在osd端收集ops信息:
1 | # ceph daemon osd.25 dump_historic_ops |
结论:
大的object size写,在osd这段处理时间很长,从 simple messager -> pg -> journal -> filestore 每一步都是串行的,单simple messager接受64M的数据就花费了117ms(10G网络),所以性能比较低,很难提升;
rbd设备
rbd到object的映射
创建一个object size为32M的rbd设备
1 | # rbd create foxtst -p cephfs_data3 --size=1024 --object-size 32M |
先写64M数据到该rbd设备
1 | # dd if=/dev/zero of=/dev/rbd0 bs=64M count=1 oflag=direct |
获取rbd设备的id
1 | # rados -p cephfs_data3 get rbd_id.foxtst myfile |
找到rbd设备对应的rados object,这里我们就写了64M数据,所以就能找到两个32M的objects
1 | # rados ls -p cephfs_data3 | grep 56092238e1f29 |
找到上述两个object的location
1 | # ceph osd map cephfs_data3 rbd_data.56092238e1f29.0000000000000000 |
性能测试
在对应osd节点上打开op tracker后,开始测试
1 | # dd if=/dev/zero of=/dev/rbd0 bs=64M count=1 oflag=direct |
在对应的osd节点上收集ops信息:
1 | # ceph daemon osd.21 dump_historic_ops > osd-21-dump_historic_ops |
分析这些ops信息可以得到以下结果:
- 写单个32M object会拆分很多个ops,拆分规则与device的max_sectors_kb配置有关系,默认这个值为:512
- 写单个32M object的ops会顺序发给osd,但不是等待一个op返回后再发下一个
- 写单个32M object的ops是流水线的处理模式;
simple messager -> pg -> journal -> filestore,所以这样处理多个小请求的效率更高,不会有cephfs中大object写会在simple messager里等待数据都全部接受后再走下一步的问题 - 写两个32M object的ops是并行的,因为这里指定的bs=64M,对应到两个不同的osd上,不同osd上的ops没先后关系
如下图所示: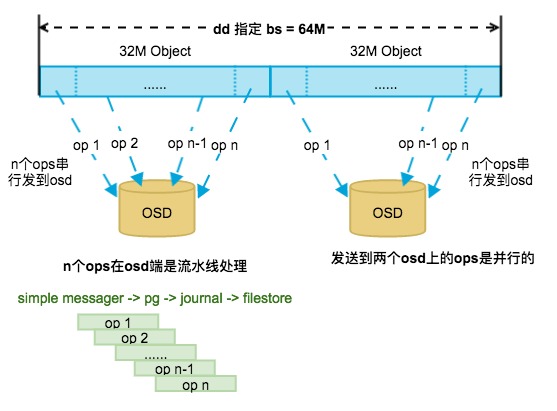
所以rbd设备的direct IO写的性能随着bs的增大是逐渐提高的。

