Trove简介
Openstack Trove项目是Openstack开源代码中提供Database As A Service的项目,它的目的是提供一个Database的框架,集成现有常见的关系型数据库、非关系型数据库。
现在Trove项目支持的数据库有:Mysql,Redis,MoogoDB,Cassandra,Couchbase,Couchdb, DB2,Postgresql,Vertica;
上述数据库中,Mysql的支持是最完善和最稳定的,别的数据库多半还在试验阶段,有些仅能提供一些数据库操作的基本功能;
Trove Docs:https://docs.openstack.org/developer/trove/
Trove Wiki:https://wiki.openstack.org/wiki/Trove
Trove源码:https://github.com/openstack/trove
Openstack Trove基于Openstack的别的模块来提供Dbaas的服务,使用到的模块有:Glance,Nova,Cinder,Neutron,Keystone,Swift;
注释:本文对应的Trove版本为Kilo
Trove架构
Openstack Trove的架构如下: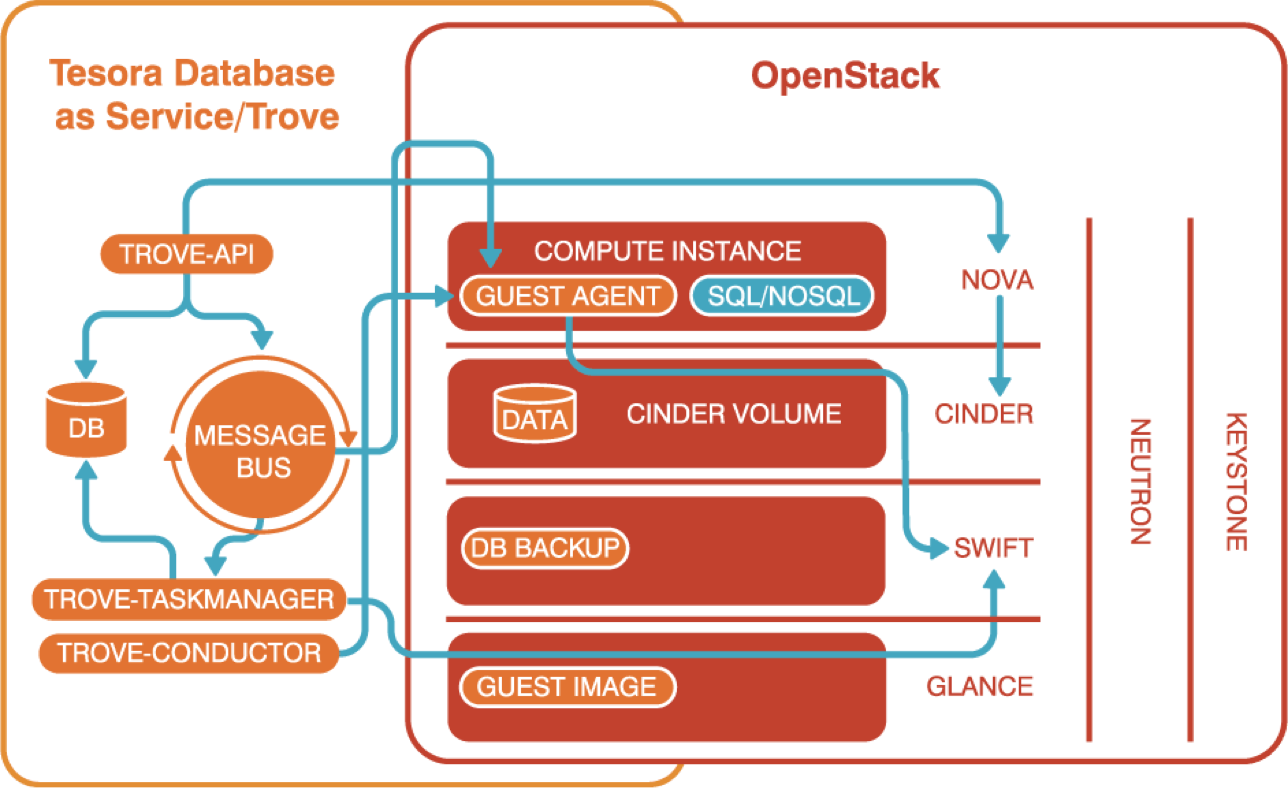
Trove Instance:指的是通过trove命令创建的一个实例,如上图所示,它实际上是一个nova instance,在里面运行了指定的database服务,同时它也会跟glance、cinder、neutron、swift打交道。
Trove有四个基本的模块,简介如下:
Trove-API
Trove的API模块,接受Trove的命令来操作数据库,然后异步交给Trove-Taskmanager执行,中间会保存Trove Instance状态到database中;
Trove-Taskmanager
Trove的任务管理模块,主要接受Trove-API发来的请求,Trove执行的主要逻辑都在这里实现,中间会更新Trove Instance状态到database中;
Trove-Conductor
Trove的信息接收模块,它接收Trove Instance的心跳信息,把Trove Instance的状态信息保存到trove使用的database中;
Trove-Guestagent
Trove的客户端代理模块,它运行在每个Trove Instance上,接收Trove-Taskmanger的命令并执行,上报Trove Instance的状态信息到Trove-Conductor;
Trove的四个模块之间通信也是使用Rabbitmq,可以使用openstack其他模块使用的Rabbitmq,也可以单独部署Rabbitmq使用;
Trove命令
Trove服务都是通过CLI命令或者Restful请求执行的,支持的命令有如下几类:
1. Instance操作
* create:创建一个trove实例
* delete:删除一个trove实例
* resize-instance:resize trove实例到新的flavor
* resize-volume:resize trove实例的volume到更大值
* restart:重启一个trove实例
* show:显示一个trove实例的detail信息
* update:更新一个trove实例的信息
2. datastore操作
datastore的创建和更新是通过 trove-manager 命令生成的;
* datastore-list:显示有哪些datastore
* datastore-show:显示一个datastore的detail信息
* datastore-version-list:显示一个datastore的version list
* datastore-version-show:显示一个datastore的一个version的detail信息
3. backup操作
trove提供备份instance到swift的操作,支持全量备份和增量备份,看具体database的实现;
* backup-create:创建一个instance的backup
* backup-delete:删除指定ID的backup
* backup-list:列出可用的所有backups
* backup-list-instance:列出指定instance的可用的所有backups
* backup-show:显示指定ID的backu的detail信息
* backup-copy:从一个backup copy生成一个新的backup
4. cluster操作
针对有些database才有cluster的概念,比如MoogoDB;
* cluster-create:创建一个新的cluster
* cluster-delete:删除一个cluster
* cluster-instances:列出一个cluster的所有instances
* cluster-list:列出所有的clusters
* cluster-show:显示指定ID的cluster的detail信息
5. configuration group操作
trove提出了配置组的概念,这是为了是用户可以定制不同instance的配置参数,针对不同的database,支持的配置参数也不相同,详细请参考代码;
比如mysql支持的配置参数定义在:trove/templates/mysql/validation-rules.json
trove限制每个instance只能配置一个configuration group
* configuration-create:创建一个新的configuration group
* configuration-delete:删除一个configuration group
* configuration-attach:attach一个configuration group到一个trove instance上
* configuration-detach:detach一个trove instance上的configuration group
* configuration-default:显示一个trove instance的默认configuration group
* configuration-instances:显示绑定到一个configuration group上的所有trove instances
* configuration-list:显示所有的configuration group
* configuration-show:显示一个configuration group的detail信息
* configuration-parameter-list:列出指定version的datastore支持的configuration group配置参数
* configuration-parameter-show:显示指定version的datastore支持的configuration group的某一项配置的详细信息
* configuration-patch:把新的<values> patch到一个configuration group
* configuration-update:更新一个configuration group的信息
6. replica操作
为了支持database的高可用,trove提供命令来创建一个trove instance的replica instance,并根据不同的database做不同的配置;
通过create命令创建一个instance的replica instance
trove create [--replica_of <source_instance>] [--replica_count <count>]
7. user操作
trove支持创建一个instance的user,并支持赋予/收回 user访问databases的权限;
* user-create:创建一个instance的user
* user-delete:删除一个instance的user
* user-grant-access:赋予user访问database(可以同时指定多个)的权限
* user-revoke-access:收回user访问database的权限
* user-list:list一个instance的所有users
* user-show:显示一个instance指定user的detail信息
* user-show-access:显示一个instance指定user访问database的权限信息
8. database操作
trove支持在一个trove instance上有多个database;
* database-create:在一个instance上创建database
* database-delete:删除一个instance上的database
* database-list:list一个instance上的所有databases
9. metadata操作
这部分应该是给trove instance打些特定标签使用的,我们使用中并没用到;
Trove代码结构
下载完trove代码后进入trove/目录,看到如下的目录结构:
基本可以通过目录的命名就知道每个目录中代码的作用了,下面列举几个常用目录的代码部分:
cluster
trove cluster实例的相关代码;
conductor
trove conductor模块的相关代码;
taskmanager
trove taskmanager模块的相关代码,这部分代码比较重要;
configuration
trove configuration group逻辑的相关代码;
guestagent
trove guestagent模块的相关代码,不同数据库的不同实现都在该目录下,目录结构如下:

templates
trove支持的各个database的模板文件,包括配置模板和configuration group模板;
backup
trove backup逻辑的相关代码;
datastore
trove datastore逻辑的相关代码;
instance
trove instance的相关代码;
创建Trove实例的过程
这里通过trove create一个instance的过程,来描述trove是如何工作的;
通过trove命令触发create操作;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15usage: trove create <name> <flavor_id>
[--size <size>] [--volume_type <type>]
[--databases <databases> [<databases> ...]]
[--users <users> [<users> ...]] [--backup <backup>]
[--availability_zone <availability_zone>]
[--datastore <datastore>]
[--datastore_version <datastore_version>]
[--nic <net-id=net-uuid,v4-fixed-ip=ip-addr,port-id=port-uuid>]
[--configuration <configuration>]
[--replica_of <source_instance>] [--replica_count <count>]
[--virtual_ip <vip>] [--vrid <vrid>]
[--sec_group_id <sec_group_id>]
[--root_password <root_password>]
error: too few arguments
Try 'trove help create' for more information.trove api收到create一个instance的请求,创建一个trove instance的实例,并把实例状态置为:building,写入database;
1
2
3
4
5
6
7
8
9
10
11
12
13def _create_resources():
...
db_info = DBInstance.create(name=instance_name,
flavor_id=flavor_id,
tenant_id=context.tenant,
volume_size=volume_size,
datastore_version_id=datastore_version.id,
task_status=InstanceTasks.BUILDING,
configuration_id=configuration_id,
slave_of_id=slave_of_id,
type=volume_type,
virtual_ip_vrid=virtual_ip_vrid)
...trove api发送异步请求给trove taskmanager,然后返回给用户,此时用户通过trove list命令可以看到trove instance的状态为building;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25def create_instance(self, instance_id, name, flavor,
image_id, databases, users, datastore_manager,
packages, volume_size, backup_id=None,
availability_zone=None, root_password=None,
nics=None, overrides=None, slave_of_id=None,
cluster_config=None, volume_type=None):
LOG.debug("Making async call to create instance %s " % instance_id)
cctxt = self.client.prepare(version=self.version_cap)
cctxt.cast(self.context, "create_instance",
instance_id=instance_id, name=name,
flavor=self._transform_obj(flavor),
image_id=image_id,
databases=databases,
users=users,
datastore_manager=datastore_manager,
packages=packages,
volume_size=volume_size,
backup_id=backup_id,
availability_zone=availability_zone,
root_password=root_password,
nics=nics,
overrides=overrides,
slave_of_id=slave_of_id,
cluster_config=cluster_config,
volume_type=volume_type)trove taskmanager根据参数调用cinder接口创建 –size
指定的volume,并等待返回;若出错则置实例状态为特定error; 1
2
3
4
5
6
7
8
9
10
11def _build_volume_info(self, datastore_manager, volume_size=None,
volume_type=None, master_vol_host=None):
...
if volume_support:
try:
volume_info = self._create_volume(volume_size,
datastore_manager,
volume_type,
master_vol_host)
except Exception as e:
...trove taskmanager根据参数调用nova接口创建nova instance;会传入 cinder volume信息,glance image信息,网络信息等等;并等待nova instance创建成功返回;若出错则置实例状态为特定error;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17def _create_server(self, flavor, image_id, security_groups,
datastore_manager, block_device_mapping,
availability_zone, nics, files={}):
userdata = self._prepare_userdata(datastore_manager, flavor)
name = self.hostname or self.name
bdmap = block_device_mapping
config_drive = CONF.use_nova_server_config_drive
server = self.nova_client.servers.create(
name, image_id, flavor['id'], files=files, userdata=userdata,
security_groups=security_groups, block_device_mapping=bdmap,
availability_zone=availability_zone, nics=nics,
config_drive=config_drive)
LOG.debug("Created new compute instance %(server_id)s "
"for instance %(id)s" %
{'server_id': server.id, 'id': self.id})
return servertrove taskmanager调用_guest_prepare发请求给trove instance里面的guestagent进程;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15def _guest_prepare(self, flavor_ram, volume_info,
packages, databases, users, backup_info=None,
config_contents=None, root_password=None,
overrides=None, cluster_config=None, snapshot=None):
LOG.debug("Entering guest_prepare")
# Now wait for the response from the create to do additional work
self.guest.prepare(flavor_ram, packages, databases, users,
device_path=volume_info['device_path'],
mount_point=volume_info['mount_point'],
backup_info=backup_info,
config_contents=config_contents,
root_password=root_password,
overrides=overrides,
cluster_config=cluster_config,
snapshot=snapshot)trove guestagent收到请求后,会根据不同database中guestagent的实现做不同操作
以mysql为例,mysql的guestagent会做如下操作:
1
2
3
4
5
6
7
8
9
10
11
12* stop database
* cinder volume格式化,并mount到指定目录
* 把之前database目录下的东西迁移到cinder volume mount的目录
* start database
* 根据传入的参数决定是否做:create database,create user,enable replica的操作
* 发送消息给trove conductor修改trove instance状态为running
trove/guestagent/datastore/mysql/manager.py文件:
def prepare(self, context, packages, databases, memory_mb, users,
device_path=None, mount_point=None, backup_info=None,
config_contents=None, root_password=None, overrides=None,
cluster_config=None, snapshot=None):trove创建instance的过程完成,此时用户通过trove list命令可以看到trove instance的状态为active;
参考资料
https://www.openstack.org/summit/openstack-summit-atlanta-2014/session-videos/presentation/introduction-to-openstack-trove-a-multi-database-deployment-with-mongodb-and-mysql
http://www.slideshare.net/ToruMakabe/openstack-trove
http://tech.it168.com/a2016/0407/2587/000002587322.shtml
http://blog.csdn.net/myproudcodelife/article/details/39839891
http://www.odbms.org/2016/02/10-things-you-should-know-about-openstack-trove-the-open-source-database-as-a-service/

