现象
当ceph在做数据迁移的时候,有一个节点的系统load很高,通过top命令可以看到如下信息:
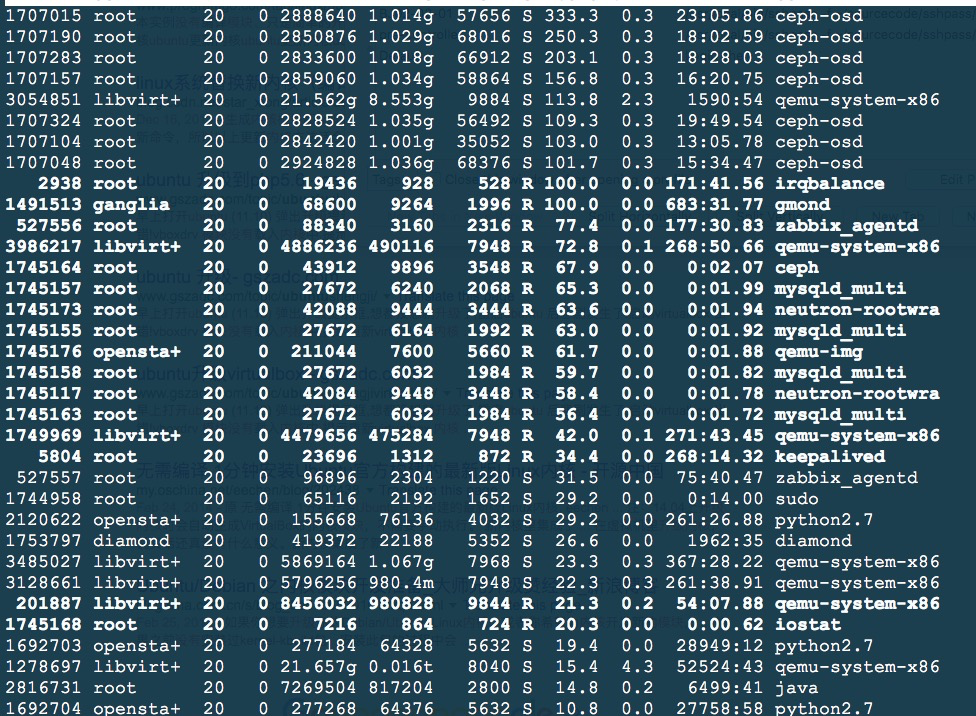
从上图中可以看出,ceph-osd占的cpu很高,这个比较奇怪。。。
对比别的机器上的ceph配置,没找到差异信息。
分析
在该机器上安装perf工具,通过perf看到如下数据:perf top -p <ceph-osd-pid>
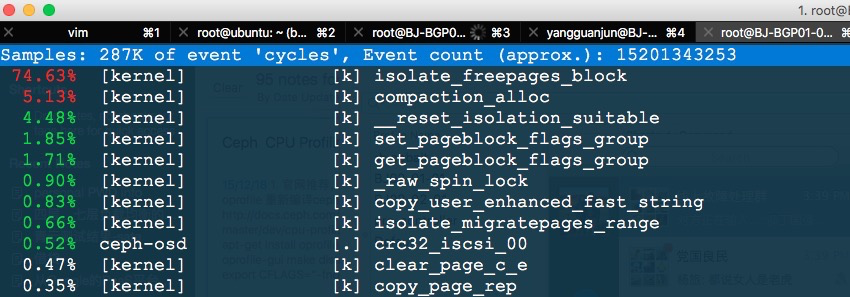
从上面的输出中看出,ceph-osd很多的时间花费在内核内存分配函数:isolate_freepages_block
搜索网上的信息,都是两年前的帖子,而我们用的ceph版本为: Hammer 0.94.5-1,不应该出这个问题。
查看该机器上的内存信息,发现free的内存很少,执行命令把内存释放掉:
sync; echo 3 > /proc/sys/vm/drop_caches
然后继续触发数据迁移,在该机器上监控系统load和ceph-osd的 perf top输出:
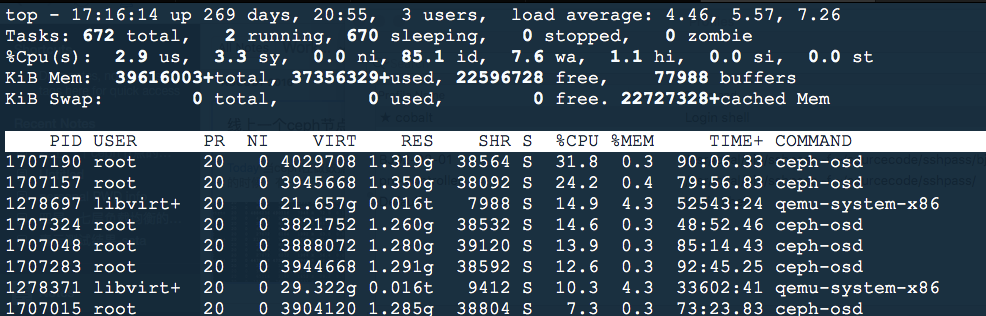
这时候系统的负载正常,ceph-osd也没有花费太多时间在内存的分配上。
问题
后续的测试中发现,当物理机的free内存很小时(约2GB),会导致ceph-osd花费较多时间在memory的分配上。
原因分析
我们系统的物理内存有256G,当free命令显示只有2GB时,可能很多都是零散的小内存了,而ceph-osd可能在运行时分配大内存,这就会触发内存页的回收和合并,所以我们就会看到ceph-osd花费很多时间在内核内存分配函数isolate_freepages_block上。
解决办法
登陆物理机,执行命令:sync; echo 3 > /proc/sys/vm/drop_caches
当然每次都手动的执行这个命令并不明智,我们把ceph节点的内存监控添加到监控项里,在监控到物理机内存小于配置值时自动触发上述命令。
参考资料
https://lkml.org/lkml/2012/6/27/545
http://lists.opennebula.org/pipermail/ceph-users-ceph.com/2014-November/044679.html

