cephfs简介
cephfs是ceph提供的兼容POSIX协议的文件系统,对比rbd和rgw功能,这个是ceph里最晚满足production ready的一个功能,它底层还是使用rados存储数据
cephfs的架构
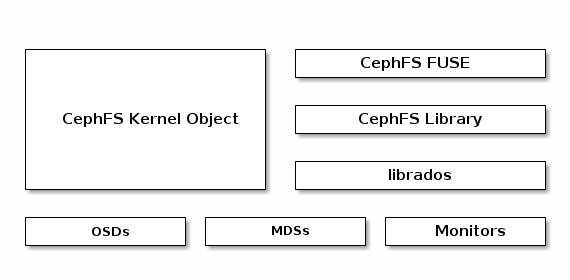
使用cephfs的两种方式
- cephfs kernel module
- cephfs-fuse
从上面的架构可以看出,cephfs-fuse的IO path比较长,性能会比cephfs kernel module的方式差一些;
client端访问cephfs的流程
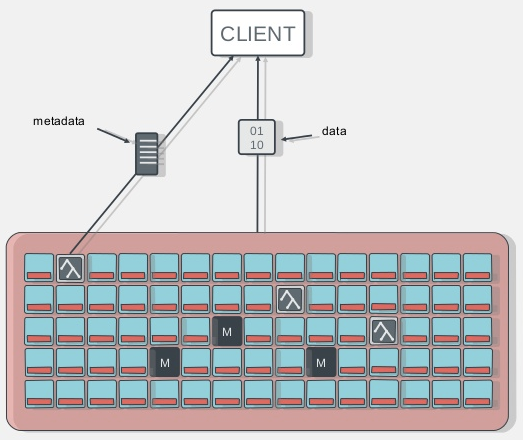
- client端与mds节点通讯,获取metadata信息(metadata也存在osd上)
- client直接写数据到osd
mds部署
使用ceph-deploy部署ceph mds很方便,只需要简单的一条命令就搞定,不过它依赖之前ceph-deploy时候生成的一些配置和keyring文件;
在之前部署ceph集群的节点目录,执行ceph-deploy mds create:
1 | # ceph-deploy --overwrite-conf mds create server1:mds-daemon-1 |
创建cephfs
创建第一个cephfs
1 | # ceph osd pool create cephfs_data 512 512 // 创建data pool |
创建第二个cephfs
默认cephfs是不支持多个fs的,这个还是试验阶段的feature,需要打开 enable_multiple 的flag
1 | # ceph osd pool create cephfs_metadata2 512 512 |
查看mds状态
ceph的mds是一个单独的daemon,它只能服务于一个cephfs,若cephfs指定多个rank了,它只能服务于其中一个rank
1 | # ceph mds stat |
对输出解释如下:
e8: e标识epoch,8是epoch号tstfs-1/1/1 up:tstfs是cephfs名字,后面的三个1分别是mds_map.in/mds_map.up/mds_map.max_mds,up是cephfs状态{[tstfs:0]=mds-daemon-1=up:active}:[tstfs:0]指tstfs的rank 0,mds-daemon-1是服务tstfs的mds daemon name,up:active是cephfs的状态为 up & active
从上面的输出可以看出,两个cephfs只有tstfs是active的,它的mds daemon为mds-daemon-1
在ceph-deploy节点添加mds-daemon-2-1
1 | # ceph mds stat |
添加新的mds daemon后,它会自动服务于一个没有mds daemon的cephfs
在ceph-deploy节点添加mds-daemon-2-2
1 | # ceph mds stat |
又添加一个新的mds daemon后,它会处于standby状态,若前两个mds daemon出问题,它会顶替上去,顶替的规则可以配置,详情参考文章:http://docs.ceph.com/docs/master/cephfs/standby/#configuring-standby-daemons
查看节点上的两个mds daemon进程
1 | [root@server2 yangguanjun]# ps aux | grep ceph-mds |
cephfs的使用
mount & umount
1 | # mount -t ceph 10.10.1.2:6789:/ /mnt/tstfs2/ |
是否支持多个cephfs?
前面我们提到可以在一个ceph cluster里创建多个cephfs,指定不同的data/metadata pool,有不同的mds daemon服务,但如何使用不同的cephfs呢?
kernel cephfs
1
2# mount -t ceph 10.10.1.2:6789:/ /mnt/tstfs2/ -o mds_namespace=tstfs
mount error 22 = Invalid argument这个问题的bug信息:http://tracker.ceph.com/issues/18161
ceph-fuse
待验证
查看cephfs状态
1 | # ceph fs get tstfs |
配置cephfs的multi mds
cephfs的multi mds属性还不是production ready,不要用在生成环境哦,自己测试下玩玩就行
1 | # ceph mds stat |
从上面输出可以看出,设置tstfs的max_mds为2后,它会自动寻找一个standby的mds daemon服务,现在看到的tstfs的信息为:tstfs-2/2/2 up和[tstfs:0]=mds-daemon-1=up:active,[tstfs:1]=mds-daemon-2-2=up:active
删除cephfs和mds
1 | 机器上停止ceph mds服务 |
参考
http://docs.ceph.com/docs/master/cephfs/
https://access.redhat.com/documentation/en-us/red_hat_ceph_storage/2/html-single/ceph_file_system_guide_technology_preview/

